Undergraduate Research Project (UGR): The Technologies
In this post we'll cover some of the technologies that were used in our South Seatte College undergraduate research project. The project involved an ensemble of different technologies to complete each component of the data analysis pipeline. Some components were planned for, but other components were implemented due to "surprise" challenges that cropped up during the course of the project, while yet more technologies were integrated into the pipeline to avoid extra costs.
Overview of the UGR Project
Before we go further, let's recap what the project was all about. As the research project mentor, I was leading a group of five undergraduate students in a project entitled "Wireless Sensor Networks for Internet of Things Applications." This involved guiding students through the construction of a data analysis pipeline that would utilize a set of sensors, each collecting data about wireless networks in the vicinity, and collect the data into a central database. We then impemented data analysis and visualization tools to analyze the sensor data that was collected and extract meaningful information from it.
There were three major sets of tools used - those used onboard the Raspberry Pi sensors (to extract and transfer wireless data), those used to store and organize the wireless sensor data (NoSQL database tools), and those used to process, analyze, and visualize the data colleted (Python data analysis tools).
The technologies used can be classified two ways:
-
Student-Led Components - the software components of the pipeline that students learned about, and whose implementation was student-led.
-
Backend Components - the software components of the pipeline that were too complicated, too hairy, and/or too extraneous to the project objectives to have students try and handle. These were the components of the project that "just worked" for the students.
Student-Led Components
Raspberry Pi
The Raspberry Pi component presented some unique challenges, with the chief being, enabling the students to actually remotely connect via SSH to a headless Raspberry Pi.
This deceptively simple task requires an intermediate knowledge of computer networking, and coupled with the obstreperous Raspberry Pi, a restrictive college network, the additional complications of students running Linux via virtual machines on Windows (all of the students were using Windows)... It ended up taking more than a month to be able to consistently boot up the Pi, remotely SSH to the Pi, and get a command line using either a crossover cable or a wireless network.
Part of this was induced by hardware, but part was due to unfamiliarity with SSH and Linux, the problems that constantly cropped up ("X is not working in the virtual machine") that were trivial for me to solve, but enigmas for the students, who often did not possess Google-fu.
Question Skills
This last point is subtle but important: the simple skill of knowing what questions to ask, and how to ask them, be they questions asked of a machine or a person or a data set, was one of the most important skills the students gained during this process. These skills go beyond the usual computer science curriculum, which consists of learning structured information in terms of languages and functionality, and require students to solve unstructured problems that are complex - so complex, they simply do not care about languages or functionality.
The flexibility to use many tools was a key element of this project, and a principal reason to use a scripting language (Python) that was flexible enough to handle the many tasks we would be asking of it.
A word about networking issues that the students had connecting to the headless Raspberry Pis:
-
Issues were due to a combination of hardware and networking problems
-
Many issues required multi-step workarounds
-
Workarounds introduced new concepts (DHCP, subnets, IP configuration schemes, IPv6)
-
Each new concept introduced led students to feel overwhelmed
-
Students had a difficult time telling what steps were "normal" and which were esoteric
-
There is a lot of documentation to read - especially difficult for non-English speakers
Each of the multitude of problems students experienced arose from different aspects of the machines. Each problem (networking, hardware, physical power, cables, networking, packet dropping, interfaces, incorrect configuration, firewalls) led to more concepts, more software, more commands.
It can be difficult to troubleshoot networking and hardware issues. It is even more difficult to explain the problem while you are troubleshooting it, and also explain things are important and that students should learn more about, versus some concept that is of questionable usefulness. (Case in point: regular expressions.) On top of that, it is difficult to constantly make judgment calls about what things are important, how important they are, and also helping students not to feel overwhelmed by all the things they don't know yet.
All the while, you are also teaching Google-fu. Did I mention that many of the students do not speak English as their first language?
Aircrack/Airodump
Once the students had reached the Raspberry Pi command line, we moved on to our next major tool - the aircrack-ng suite. This was a relatively easy tool to get working, as it was already available through a package manager (yet another new concept for the students), so we did not waste much time getting aircrack operational and gathering our first sensor data. However, to interpret the output of the tool required spending substantial time covering many aspects of networking - not just wireless networks, but general concepts like packets, MAC addresses, IP addresses, DHCP, ARP, encryption, and the 802.11 protocol specification.
Initially I had thought to use a Python library called Scapy, which provides functionality for interacting with wireless cards and wireless packets directly from Python. My bright idea was to use aircrack to show students what kind of information about wireless networks can be extracted, and to write a custom Python script that would extract only the information we were interested in.
Unfortunately, the complexity of Scapy, and the advanced level of knowledge required of users (even to follow the documentation), meant the tool overwhelmed the students. We wound up practicing putting wireless USB devices into monitor mode from the command line, and starting the wireless network signal profiling tool.
The approach we adopted was to collect wireless network data using aircrack-ng's airodump-ng tool, and to dump the network data at short intervals (15 seconds) to CSV files. These CSV files were then post-processed with Python to extract information and populate the database.
By the end of the first quarter of the project, we were able to utilize airodump-ng to collect wireless network data into CSV files, and parse the data with a Python script.
Pi CSV Files
Further complicating the process of collecting wireless network data from Raspberry Pis was the fact that we were gathering data from the Pis in a variety of different environments - most of which were unfamiliar, and would not reliably have open wireless networks or networks that the Pi was authorized to connect to. Even on the South Seattle campus, the network was locked down, with only HTTP, HTTPS, and DNS traffic allowed on ports 80, 443, and 53, respectively.
This meant we couldn't rely on the Pis making a direct connection to the remote server holding the central database.
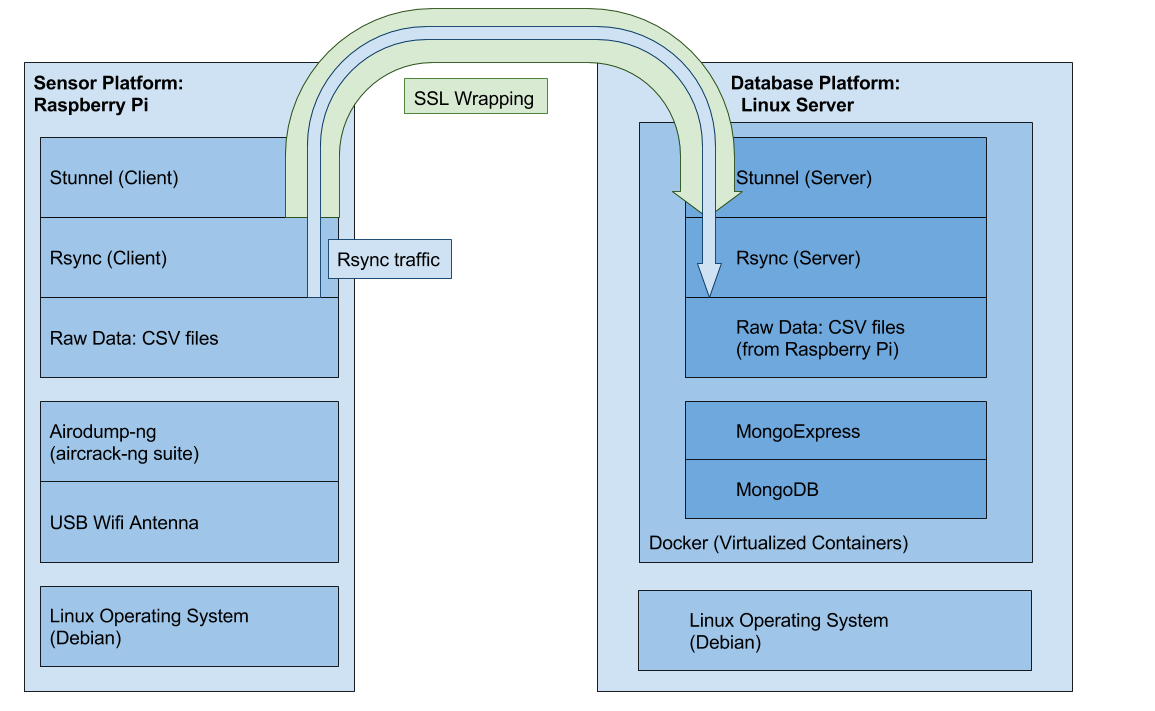
Instead, we utilized rsync to synchronize the CSV files gathered by the Pi with the remote server, and we offloaded the process of extracting and analyzing data from the CSV files to a script on the remote server.
That way, the Pis gather the raw data and shuttle the raw data to the remote server (whenever it is available), and the data extraction and analysis process can be performed on the raw data in the CSV files as many times as necessary. If the analysis required different data, or needed to be re-run, the process could simply be updated and re-run on the databae server, with the Raspberry Pi removed from the loop.
NoSQL Database
We needed a warehouse to store the data that the Raspberry Pis were gathering. The aircrack script was dumping CSV files to disk every 15 seconds. Rather than process the data on-board the Raspberry Pi, the script to extract and process data from the CSV files was run on the computer running the database.
This is a best practice I learned form experience:
-
Extract and process the sensor data on-premises (i.e., near or where the data is stored)
-
Keep the original, raw data whenever possible, transport it to the data storage
-
Assume the components of your pipeline will be unreliable or asychronously available
-
Build the pipeline to be robust and handle failures.
We used a cheap, $5/month virtual private server from Linode to run the database. The database technology we chose was MongoDB, mainly because it is a ubiquitous, open-source, network-capable NoSQL database. The NoSQL option was chosen to give students flexibility in structuring the database, and avoid the extra pain of making a weakly-typed language like Python talk to a strongly-typed database system like SQLite or PostgreSQL (which would raise so many questions from students about what is "normal" or "not normal" that I would start to feel like the parent of a bunch of teenagers).
Think of the long-term influence that research mentors can have: simply by showing students how to use vim, and not emacs, I have set them on the path to enlightenment.
We ran the database on the server, but conceptualizing the database was difficult for the students. To this end, I set up an instance of Mongo Express, which provided a password-protected, web-based interface for administering MongoDB that enabled the students to deal with and visualize information more easily.
MongoDB also provided Python bindings via PyMongo, and it was all available for students to install on their local virtual machines and experiment with basic database operations. The MongoDB documentation provides some good examples.
The main struggle that students had was transferring what they had learned about wireless signals and aircrack to the database. Knowing what questions to ask the database proved to take most of their time.
Backend components
During the process of getting each component working, the project occasionally encountered difficulties. The chiefest among these was the fact that the wireless network at our college allowed traffic only on ports 80, 443, and 53, meaning SSH, Rsync, and MongoDB traffic would not make it past the school's firewall.
Stunnel
I have written about Stunnel before on this blog, and have some notes on Stunnel on the charlesreid1.com wiki. This tool proved invaluable for overcoming some of the difficulties on the back-end for the Raspberry Pis.
To allow the Raspberry Pis to securely send data to the database server, I wrote a script that would run on boot and would look for a list of trusted wireless networks, connect to them, and establish an stunnel connection with the remote database server. The script then used rsync over stunnel to synchronize any raw data collected by the Raspberry Pi with the remote database server.
This also satisfied the criteria that the data pipeline be robust and capable of handling failure - this system used stunnel to punch out of a restrictive firewall, and rsync handled comparisons of raw data on the remote and local ends to ensure that only the minimum possible amount of data was transferred between the two. The raw data was plain text and consisted of text files of modest size, making the job easy for rsync.
This was implemented in a boot script, so one simply connected one of the Raspberry Pis to a portable power source (battery pack), and the Pi would look for networks that it trusted, join those networks, and make an stunnel connection over the network to transfer its data (CSV files) to the database server.
Virtual Private Server
Another bit of infrastructure that was provided on the back end was the virtual private server from Linode, so that the students did not have to find a workaround to SSH out of the school's restrictive firewall. A domain for the server was also purchased/provided.
Docker
The virtual private server ran each service in a Docker container - stunnel, MongoDB, MongoExpress, and the long list of Python tools needed to run the Jupyter notebooks for data analysis.
Each Docker container exposed a particular port, making it accessible at an appropriate scope, and by connecting containers to other containers, each component could also seamlessly communicate. Thus one Docker container ran the MongoDB, while another container ran MongoExpress, which established a connection to the MongoDB container.
Using Docker was not strictly necessary, but it was a good opportunity to learn about Docker and get it set up to help solve real-world infrastructure and service problems.
Technologies Flowchart
The following flowchart shows the technology stack that was used to coordinate the various moving parts between the Raspberry Pi clients and the remote database server.